codePointAt
The codePointAt task retrieves the Unicode value for a character at a specific position in a string. The result is a non-negative integer representing the code point value of the character at the given position.
Potential use case
This task helps with multilingual text and localization. If you have a dataset containing unique language characters, use codePointAt to return the code point value for each character and handle them according to the Unicode standard.
Properties
Example
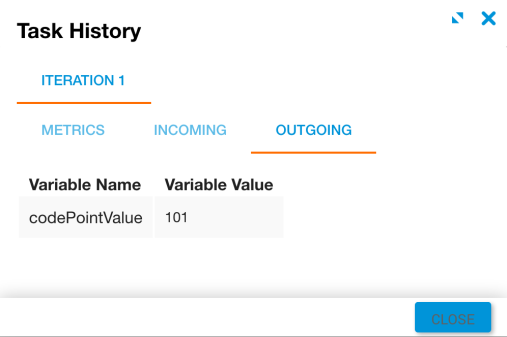
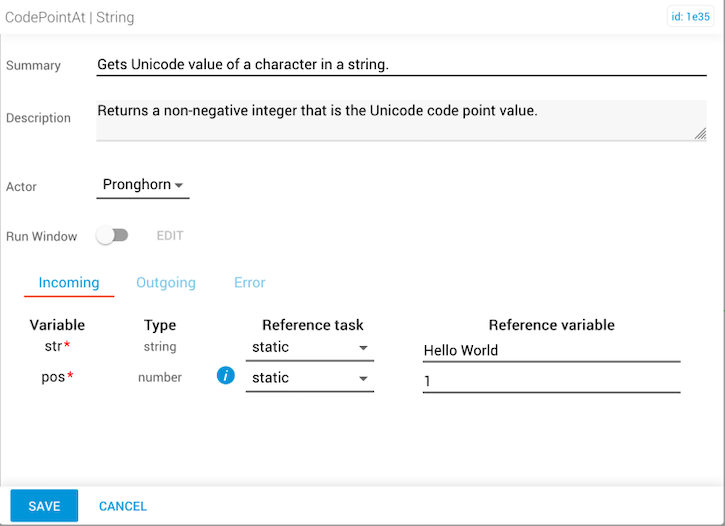
The incoming str is "Hello World" and the pos is 1, which corresponds to the letter "e".
The first character position is 0, the second is 1, and so on.
The codePointValue returned is 101, which is the Unicode value for the lowercase letter "e".